PhD Thesis: Diego Omar Encinas: March 20, 2026
Title: Modelización y simulación basada en agentes aplicada a la arquitectura de entrada/salida de los computadores paralelos.
TDX Source: https://sedici.unlp.edu.ar/handle/10915/194710

The general objective of this thesis is to develop a model of the I/O subsystem in High Performance Computing (HPC) environments capable of predicting how changes in hardware and software components affect both the functionality and performance of parallel I/O systems. The work focuses on the application of Agent-Based Modeling and Simulation (ABMS) to represent the complex interactions within the I/O software stack, with particular emphasis on parallel file systems.
The main contributions are as follows:
The definition of an agent-based model for representing the hardware and software components involved in parallel I/O architectures in HPC systems.
The characterization of the interactions among the different layers of the I/O software stack, including application, middleware, and parallel file system components.
The design and implementation of SABIOS (Simulator for Agent-Based I/O System), a simulation tool capable of modeling and visualizing the behavior of HPC I/O systems under different configurations.
A detailed representation of the agents and communication mechanisms involved in the operation of the PVFS2 parallel file system.
The evaluation of the impact of different I/O configurations and architectural parameters on system functionality and performance.
The demonstration of how ABMS can be used to quantify and visualize the temporal and spatial behavior of parallel I/O systems, enabling the analysis of bottlenecks and optimization opportunities in HPC environments.
The results obtained with SABIOS demonstrate the effectiveness of agent-based simulation for studying complex I/O architectures, providing a flexible framework for analyzing performance, scalability, and the interaction between the different layers of the parallel I/O stack.
PhD Thesis: Marina Morán: April 25, 2025 (Associate Professor Universidad Nacional del Comahue, Argentina)
Title: Modelización y gestión del consumo energético en un sistema de computación de altas prestaciones con tolerancia a fallos.

TDX Source: https://sedici.unlp.edu.ar/handle/10915/180599

The general objective of this thesis is to identify and manage the potential for energy savings when using the fault tolerance method based on checkpoint/restart in high-performance computing systems. The main contributions are as follows:
A method for building energy consumption prediction models for system-level coordinated checkpoint/restart in SPMD applications with homogeneous rollbacks.
An energy consumption prediction model for checkpoint/restart applied to a heat propagation application following the SPMD parallel programming paradigm.
A study of system (hardware and software) and application-level factors that affect the energy consumption generated by checkpoint and restart operations.
The definition of a series of energy-saving strategies in the event of a failure, where only the failed processes are recovered, considering that they communicate directly and indirectly with the failed process.
The definition of a model to evaluate the impact of applying these strategies on energy consumption under different scenarios.
The design and development of a simulator that utilizes the model above enables the evaluation of the proposed strategies and determines the most energy-efficient one.
PhD Thesis: Felipe Leonardo Tirado Marabolí: April 4, 2024 (Associate Professor Universidad Católica del Maule, Talca, Chile)
Title: Caracterización de aplicaciones con comportamiento irregular para predecir su rendimiento, basado en la filosofía PAS2P.
TDX Source: To be published
 Modeling parallel scientific applications allows us to understand the intricacies of parallel application behavior. Many scientific applications exhibit irregular behavior, which makes it difficult to obtain the model that characterizes the application. This difficulty is mainly due to their non-deterministic pattern of communication and computation. One way to obtain information from the applications is through analysis tools. The PAS2P tool, based on application repeatability, focuses on performance analysis and prediction using the application signature. It uses the same resources that run the parallel application for its analysis, thus creating a machine-independent model and identifying common patterns in the application.
Modeling parallel scientific applications allows us to understand the intricacies of parallel application behavior. Many scientific applications exhibit irregular behavior, which makes it difficult to obtain the model that characterizes the application. This difficulty is mainly due to their non-deterministic pattern of communication and computation. One way to obtain information from the applications is through analysis tools. The PAS2P tool, based on application repeatability, focuses on performance analysis and prediction using the application signature. It uses the same resources that run the parallel application for its analysis, thus creating a machine-independent model and identifying common patterns in the application.
When applying the PAS2P tool to irregular applications, generating a model is impossible due to the non-homogeneous communication and computation pattern that prevents finding a repeatability pattern, ma- king it difficult to obtain a model that characterizes the behavior of these applications.
Due to the above, we present a modeling methodology for irregular parallel applications that analyzes data by processes. This approach successfully characterizes the application based on the behavior of each process. To effectively characterize irregular applications, we group the repeatability patterns of all the processes executing the application into a single model. The model that characterizes the behavior of the irregular parallel application can be used to analyze and predict the execution time of the application on a target machine.
The experimental validation of the proposed model called “Extension of PAS2P for irregular applications” demonstrates a reduction in the communications performed by PAS2P, which implies a decrease in the time required for the application analysis. Furthermore, it is possible to characterize irregular applications, establishing a machine-independent model that can predict the execution time with an average error of less than 9 %.
PhD Thesis: Betzabeth del Carmen León Otero: March 9, 2023. (Associate Professor UAB)
Title: Gestión del Almacenamiento para Tolerancia a Fallos en Computación de Altas Prestaciones.
TDX Source: http://hdl.handle.net/10803/689691
 In HPC environments, it is essential to keep applications that require a long execution time running continuously. Redundancy is one of the methods used in HPC as a protection strategy against any failure, but generating an overhead due to redundant information implies additional time and resources to ensure the correct functioning of the system.
In HPC environments, it is essential to keep applications that require a long execution time running continuously. Redundancy is one of the methods used in HPC as a protection strategy against any failure, but generating an overhead due to redundant information implies additional time and resources to ensure the correct functioning of the system.
Fault tolerance has become fundamental in ensuring system availability in high-performance computing environments. Among the strategies used is the rollback recovery, which consists of returning to a previous correct state previously saved. Checkpoints allow information on the state of a process to be saved periodically in a stable storage system.
Still, a lot of latency is involved as all processes are concurrently accessing the file system. Also, checkpoint storage can affect parallel application performance and scalability that uses message passing. Therefore, it is important to know the elements that can impact checkpoint storage and how they can influence the scalability of a fault-tolerant application. For example, characterizing the files generated when performing the checkpoint of a parallel application is useful to determine the resources consumed and their impact on the I/O system. It is also important to characterize the application that performs the checkpoint because the I/O of the checkpoint depends mainly on it.
The present research proposes a methodology that helps in configuring stable storage of the I/O files generated by fault tolerance, considering the access patterns to the generated files and the user requirements. This methodology has three phases in which the I/O patterns of the checkpoint are characterized. Then, the stable storage requirements are analyzed, and the behavior of the fault tolerance strategy is modeled.
A model of prediction of checkpoint scalability has been proposed as part of the last phase of the methodology. This methodology can be useful when selecting which type of checkpoint configuration is most appropriate based on the characteristics of
the applications and the available resources. Thus, the user will know how much storage space the checkpoint consumes and how much the application consumes to establish policies that help improve the distribution of resources.
PhD Thesis: Ghazal Tashakor: January 26, 2021, 18:00 (Postdoc at Jülich Research Center – DEEP projects).
Title: Scalable agent-based model simulation using distributed computing on system biology.
TDX Source: http://hdl.handle.net/10803/671332
 Abstract: Agent-based modeling is a very useful computational tool to simulate complex behavior using rules at micro and macro scales. This type of modeling’s complexity is in defining the rules that the agents will have to define the structural elements or the static and dynamic behavior patterns. This thesis considers the definition of complex models of biological networks that represent cancer cells obtain behaviors on different scenarios by means of simulation and to know the evolution of the metastatic process for non-expert users of computer systems.
Abstract: Agent-based modeling is a very useful computational tool to simulate complex behavior using rules at micro and macro scales. This type of modeling’s complexity is in defining the rules that the agents will have to define the structural elements or the static and dynamic behavior patterns. This thesis considers the definition of complex models of biological networks that represent cancer cells obtain behaviors on different scenarios by means of simulation and to know the evolution of the metastatic process for non-expert users of computer systems.
Besides, a proof of concept has been developed to incorporate dynamic network analysis techniques and machine learning in agent-based models based on developing a federated simulation system to improve the decision-making process. For this thesis’s development, the representation of complex biological networks based on graphs has been analyzed, from the simulation point of view, to investigate how to integrate the topology and functions of this type of networks interacting with an agent-based
model. For this purpose, the ABM model has been used as a basis for the construction, grouping, and classification of the network elements representing the structure of a complex and scalable biological network.
The simulation of complex models with multiple scales and multiple agents provides a useful tool for a scientist, non-computer expert to execute a complex parametric model and use it to analyze scenarios or predict variations according to the different patient’s profiles.
The development has focused on an agent-based tumor model that has evolved from a simple and well-known ABM model. The variables and dynamics referenced by the Hallmarks of Cancer have been incorporated into a complex model based on graphs. Based on graphs, this model is used to represent different levels of interaction and dynamics within cells in the evolution of a tumor with different degrees of representations (at the molecular/cellular level).
A simulation environment and workflow have been created to build a complex, scalable network based on a tumor growth scenario. In this environment, dynamic techniques are applied to know the tumor network’s growth using different patterns. The experimentation has been carried out using the simulation environment developed considering the execution of models for different patient profiles, as a sample of its functionality, to calculate parameters of interest for the non-computer expert, such as the evolution of the tumor volume.
PhD Thesis: Elham Shojaei: October 19 2020, 10:30. (Researcher at Leibniz Rechenzentrum, der Bayerischen Akademie der Wissenschaften)
Title: Simulation for Investigating Impact of Dependent and Independent Factors on Emergency Department System Using High Performance Computing and Agent-based Modeling.
TDX Source: http://hdl.handle.net/10803/670856
 Abstract: Increased life expectancy, and population aging in Spain, along with their corresponding health conditions such as non-communicable diseases (NCDs), have been suggested to contribute to higher demands on the Emergency Department (ED). Spain is one of such countries which an ED is occupied by a very high burden of patients with NCDs. They very often need to access healthcare systems and many of them need to be readmitted even though they are not in an emergency or dangerous situations. Furthermore many NCDs are a consequence of lifestyle choices that can be controllable. Usually, the living conditions of each chronic patient affect health variables and change the quantity of these health variables, so they can change the stability situation of the patients with NCDs to instability and its resultant will be visiting ED.
Abstract: Increased life expectancy, and population aging in Spain, along with their corresponding health conditions such as non-communicable diseases (NCDs), have been suggested to contribute to higher demands on the Emergency Department (ED). Spain is one of such countries which an ED is occupied by a very high burden of patients with NCDs. They very often need to access healthcare systems and many of them need to be readmitted even though they are not in an emergency or dangerous situations. Furthermore many NCDs are a consequence of lifestyle choices that can be controllable. Usually, the living conditions of each chronic patient affect health variables and change the quantity of these health variables, so they can change the stability situation of the patients with NCDs to instability and its resultant will be visiting ED.
In this study, a new method for the prediction of future performance and demand in the emergency department (ED) in Spain is presented. Prediction and quantification of the behavior of ED are, however, challenging as ED is one of the most complex
parts of hospitals. Future years of Spain’s ED behavior was predicted by the use of detailed computational approaches integrated with clinical data. First, statistical models were developed to predict how the population and age distribution of patients
with non-communicable diseases change in Spain in future years. Then, an agent-based modeling approach was used for simulation of the emergency department to predict impacts of the changes in population and age distribution of patients with NCDs on the performance of ED, reflected in hospital LoS, between years 2019 and 2039.
Then in another part of this study, we propose a model that helps to analyze the behavior of chronic disease patients with a focus on heart failure patients based on their lifestyle. We consider how living conditions affect the signs and symptoms of chronic disease and, accordingly, how these signs and symptoms affect chronic disease stability. We use an agent-based model, a state machine, and a fuzzy logic system to develop the model. Specifically, we model the required ’living condition’ parameters that can influence the required medical variables. These variables determine the stability class of chronic disease.
This thesis also investigates the impacts of Tele-ED on behavior, time, and efficiency of ED and hospital utilization. Then we propose a model for Tele-ED which delivers the medical services online. Simulation and Agent-based modeling are powerful tools that allow us to model and predict the behavior of ED as a complex system for VIa given set of desired inputs. Each agent based on a set of rules responds to its environment and other agents. This thesis can answer several questions in regards to the demand and performance of ED in the future and provides health care providers with quantitative information on economic impact, affordability, required staff, and physical resources. Prediction of the behavior of patients with NCDs can also be beneficial for health policy to plan for increasing health education in the community, reduce risky behavior, and teaching to make healthy decisions in a lifetime. Prediction of behavior of Spain’s ED in future years can help care providers for decision-makers to improve health care management.
PhD Thesis: Diego Montezanti: March 18, 2020 09:00 (ARG). (Researcher at III-LIDI UNLP)
Title: Soft Error Detection and Automatic Recovery in High Performance Computing Systems (SEDAR).
TDX Source: http://sedici.unlp.edu.ar/handle/10915/104331
 Abstract:
Abstract:
Reliability and fault tolerance have become aspects of growing relevance in the field of HPC, due to the increased probability that faults of different kinds will occur in these systems. This is fundamentally due to the increasing complexity of the processors, in the search to improve performance, which leads to a rise in the scale of integration and in the number of components that work near their technological limits, being increasingly prone to failures. Another factor that affects is the growth in the size of parallel systems to obtain greater computational power, in terms of number of cores and processing nodes.
As applications demand longer uninterrupted computation times, the impact of faults grows, due to the cost of relaunching an execution that was aborted due to the occurrence of a fault or concluded with erroneous results. Consequently, it is necessary to run these applications on highly available and reliable systems, requiring strategies capable of providing detection, protection and recovery against faults.
In the next years it is planned to reach Exa-scale, in which there will be supercomputers with millions of processing cores, capable of performing on the order of 1018 operations per second. This is a great window of opportunity for HPC applications, but it also increases the risk that they will not complete their executions. Recent studies show that, as systems continue to include more processors, the Mean Time Between Errors decreases, resulting in higher failure rates and increased risk of corrupted results; large parallel applications are expected to deal with errors that occur every few minutes, requiring external help to progress efficiently. Silent Data Corruptions are the most dangerous errors that can occur, since they can generate incorrect results in programs that appear to execute correctly. Scientific applications and large-scale simulations are the most affected, making silent error handling the main challenge towards resilience in HPC. In message passing applications, a silent error, affecting a single task, can produce a pattern of corruption that spreads to all communicating processes; in the worst case scenario, the erroneous final results cannot be detected at the end of the execution and will be taken as correct.
Since scientific applications have execution times of the order of hours or even days, it is essential to find strategies that allow applications to reach correct solutions in a bounded time, despite the underlying failures. These strategies also prevent energy consumption from skyrocketing, since if they are not used, the executions should be launched again from the beginning. However, the most popular parallel programming models used in supercomputers lack support for fault tolerance.
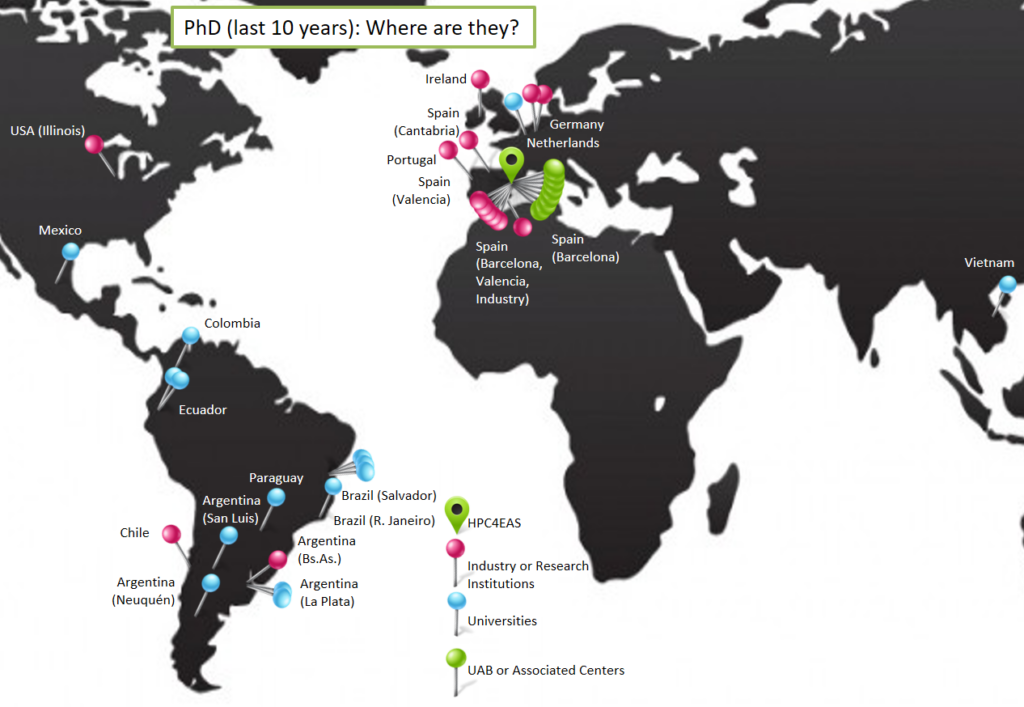
PhD Thesis supervised by members of the group:
- Fault Tolerance Configuration and Management for HPC Applications using RADIC. Jorge Luis Villamayor Leguizamón. (2018) R&D Product Owner / IT Project Manager at Giesecke+Devrient Mobile Security. Spain.
- Efficient Communication Management in Cloud Environments. Laura María Espínola Brítez (2018) R&D QA Manager at Giesecke+Devrient Mobile Security. Spain.
- Analyzing the Parallel Applications’ I/O Behavior Impact on HPC Systems. Pilar Gómez Sánchez (2018) Researcher at private industry. Spain.
- Modelización y Simulación de la transmisión por contacto de una infección nosocomial en el servicio de urgencias hospitalarias. Cecilia Elizabeth Jaramillo Jaramillo (2017) Researcher at Computer Science Department. Universidad ISRAEL. Quito, Ecuador.
- Scheduling non critical patients’ admission in a hospital emergency department. Eva Bruballa (2017) Assistant Professor at Gimbernat Schools, Spain.
- Mejorando la red de los servicios de motores de búsqueda a través de enrutameinto basado en aplicación. Joe Carrion Jumbo (2017) Researcher at Computer Science Department. Universidad ISRAEL. Quito, Ecuador.
- Care HPS: A High Performance Simulation Methodology for Complex Agent-Based Models. Francisco Borges (2016) Assistant Professor at IFBA Instituto Federal de Educação, Ciência e Tecnologia da Bahia, Campus Santo Amaro. Bahia. Brazil.
- Crowd Modeling and Simulation on High Performance Architectures. Albert Gutiérrez Millà (2016). Researcher at Barcelona Supercomputing Center. CASE – Fusion Dpt.- Barcelona-Spain
- Modeling & Simulation for Healtcare Operations Management Using High Performance Computing & Agent Based Model. Liu Zhengchun (2016). Researcher at Argonne National Laboratory. MSC Dpt. USA. Outstanding dissertation award
- Performane Prediction: analysis of the scalability of parallel applications. Javier Panadero Martínez (2015) (Researcher at Internet Interdisciplinary Institute (IN3) – Universitat Oberta de Catalunya. Barcelona-Spain)
- Simulación y Optimización como Metodología para Mejorar la Calidad de la Predicción en un Entorno de Simulación Hidrográfica. Adriana Gaudiani (2015) (Associate Researcher at Science Institute. Universidad Nacional de General Sarmiento, Buenos Aires, Argentina)
- A dynamic link speed mechanism for energy Saving in interconnection networks. Hai Nguyen Hoang (2014) (Lecturer in Information Technology Faculty. Danang University of Education. Danang University. Vietnam)
- ARTFUL Deterministically Assessing the Robustness against Transient Faults of Programs.João Artur Dias Lima Gramacho (2014) (Software Analyst & Developer at Oracle MySQL Replication Team. Lisbon Area, Portugal)
- Fault Tolerance in Multicore Clusters. Techniques to Balance Performance and Dependability. Hugo Meyer (2014) (Postdoctoral Research Scientist, Universiteit van Amsterdam) Outstanding dissertation award
- Modelo basado en Autómatas Celulares extendidos para diseñar estrategias de Evacuaciones en Casos de Emergencia. Cristian Tissera (2014) (Assistant professor UNSL, Argentina)
- Optimisation via simulation for healthcare emergency departments. Eduardo Cesar Cabrera Flores (2013) (Full-time Researcher at Universidad Autónoma de Guerrero (UAGro), Mexico)
- Vulnerability Assessment for Complex Middleware Interrelationships in Distributed Systems. Jairo Serrano Latorre (2013) (Security & Quality Assurance Officer in the project ECmanaged at Ack Storm S.L.)
- Predictive and Distributed Routing Balancing for High Speed Interconnection Networks. Carlos H. Núñez Castillo (2013) (Researcher, Polytechnic Faculty, Computer Science Department, National University of Asuncion)
- Tolerancia a fallos en la capa de sistema basada en la arquitectura RADIC. Marcela Castro León (2013) (Staff, Gimbernat Schools, Spain)
- Simulación de los Servicios de Urgencias Hospitalarias: una aproximación computacional desarrollada mediante técnicas de Modelado Orientadas al Individuo (Mol). Manuel Taboada González (2013). (Postgraduate Coordinator, Gimbernat Schools, Spain) Outstanding dissertation award
- Metodología para la evaluación de prestaciones del sistema Entrada/Salida en computadores de altas prestaciones. Sandra A. Méndez (2013) (Researcher at Leibniz Supercomputing Centre of the Bavarian Academy of Sciences and Humanities, Germany)
- Planificación de DAGs en entornos oportunísticos. MªMar López (2012) (Temporary lecturer, UAB)
- TDP-Shell: Entorno para acoplar gestores de colas y herramientas de monitorización. Vicente Ivars Camanes (2012) (Temporary lecturer, UAB)
- Particionamiento y Balance de Carga en Simulaciones Distribuidas de Bancos de Peces. Roberto Solar Gallardo (2012) (Assistant Professor at Universidad de Santiago de Chile).
- Multipath Fault-tolerant Routing Policies to deal with Dynamic Link Failures in High Speed Interconnection Networks. Gonzalo A. Zarza (2011) (Researcher on High-Performance Solutions & Big-Data at Globant). Outstanding dissertation award
- Fault Tolerance Configuration for Uncoordinated Checkpoints. Leonardo Fialho de Queiroz (2011) (Lab Manager at Atos/Bull, Petrópolis, Rio de Janeiro, Brazil).
- Metodología para la ejecución eficiente de aplicaciones SMPD en clústeres con procesadores multicores. Ronal Muresano Caceres (2011) (HPC and BigData senior software researcher, ITI – Instituto Tecnológico de Informática, Ciudad Politécnica de la Innovación – UPV – Spain). Outstanding dissertation award
- Performance evaluation of applications for heterogeneus systems by means of performance probes. Alexandre Strube (2011) (Researcher at Institute for Advanced Simulation & Jülich Supercomputing Centre)
- Predicción de perfiles de comportamiento de aplicaciones ciéntíficas en nodos multicore. John Corredor Franco (2011) (Associate Professor, Universidad de Pamplona, Colombia)
- Framework for integrating scheduling policies into workflow engines. Gustavo Martinez (2011) (Tecnocom, Spain)
- Firma de la aplicación paralela para predecir el rendimiento. Álvaro Wong González (2010) (Associate Researcher, Universitat Autònoma de Barcelona, Spain)
- Decentralized Scheduling on Grid Environments. Manuel Brugnoli (2010) (RIP 2014)

- R/parallel – Parallel Computing for R in non-dedicated environments. Gonzalo Vera (2010) (Scientific IT Manager and Bioinformatician. Centre for Research in Agricultural Genomics -CRAG-, Spain)
- Políticas de Encaminamiento Multicamino en redes de interconexión de altas prestaciones. Diego F. Lugones (2009) (Researcher at Rince Institute, Dublin City University, Ireland).
- Performability issues of fault tolerance solutions for message.passing systems: the case of Radic. Guna Santos (2009) (Associate Professor at Universidade Federal da Bahia, Salvador, Brazil)
- Un sistema de vídeo bajo demanda a gran escala tolerante a fallos de red. Javier A. Balladini (2008) (Associate Professor, Universidad Nacional del Comahue, Argentina)
- Scheduling for Interactive and Parallel Applications on Grids. Enol Fernández (2008) (Researcher at EGI-InSpire Project, IFCA, Spain)
- Mapping sobre arquitecturas heterogéneas. Laura De Giusti (2008) Universidad Nacional de La Plata (Associate Professor, Universidad Nacional de La PLata, Researcher at III-LIDI, Argentina)
- ¿Podemos predecir en Algoritmos Paralelos No-Deterministas? Paula Fritzsche (2007) (Researcher at Qustodian Trust SL, Spain). Outstanding dissertation award
- Simulación de altas prestaciones para modelos orientados al individuo. Diego Mostaccio (2007) (R&D Engineer at Hewlett-Packard)
- Radic: A powerful fault-tolerance architecture. Angelo Duarte (2007) (Associate Professor, Universidade Estadual de Feira de Santana, Brazil)
- Aumentando las Prestaciones en la Predicción de Flujo de Instrucciones. Juan Carlos Moure (2006) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- FTDR: Tolerancia a fallos, en clusters de computadores geográficamente distribuidos, basada en replicación de datos. Josemar Rodrigues de Souza (2006) (Associate Professor, Universidade do Estado da Bahia, Brazil).
- Performance prediction and tuning in a multicluster environment. Eduardo Argollo (2006) (Solution Architect for Cloud Applications at Hewlett-Packard, Spain)
- Admission Control and Media Delivery Subsystems for Video on Demand Proxy Server. Bahjat Qazzaz (2004) (Associate Professor, Faculty of Information Technology, An-Najah National University. Nablus, Palestine) (RIP 2019)
- Cómputo paralelo en redes locales de computadoras. Fernando Tinetti (2004) (Associate Professor, Universidad Nacional de La PLata, Researcher at III-LIDI, Argentina)
- Balanceo Distribuido del Encaminamiento en Redes de Interconexión de Computadores Paralelos. Daniel Franco (2000) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- Modelado y Simulación de Sistemas Paralelos. Remo Suppi (1996) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- Políticas de Scheduling Estático para Sistemas Multiprocesador. Porfidio Hernández (1991) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- Simulación de Arquitecturas Computacionales. M.A. Mayosky (1990) (Associate Professor, Universidad Nacional de La PLata, Researcher at LEICI, Argentina)
- Sistemas Multiprocesador con Buses Múltiples. Dolores Rexachs (1988) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- Adaptación de la Arquitectura en Tiempo de Ejecución. Joan Sorribes (1987) (Associate Professor, Universitat Autònoma de Barcelona, Spain)
- Algoritmos de Selección en el Proceso de Adaptación de la Arquitectura en un Ordenador. Tomás Díez (1987). (RIP 2004)
- Adaptación de la Arquitectura en Sistemas Microprogramables. Ana Ripoll (1980) (Professor, Universitat Autònoma de Barcelona, Spain)
- Procesador Concurrente para Bases de Datos. José Jaime Ruz Ortiz (1980) Universidad Complutense de Madrid (Professor, Universidad Complutense de Madrid. Spain).
- Concepción y desarrollo de un Procesador para Ejecución Directa de Lenguajes de Alto Nivel. Lorenzo Moreno Ruiz (1977) Universidad Complutense de Madrid (Professor, Universidad de La Laguna – Spain).