We are deeply saddened by the loss of our dear friend and colleague Manuel Brugnoli (1980-2014).

Our deepest condolences, and sympathy, to his family and especially to his wife Jennifer.
Manuel was highly esteemed and beloved by all his fellows and he always had the appreciation of all his friends and colleagues in CAOS, who valued his companionship and friendship.
Manuel arrived at the UAB in September 2006, when he was selected as a scholar in the Computer Architecture and Operating Systems (CAOS) Department. From that date on Manuel was a distinguished PhD student and later on a brilliant researcher. Manuel demonstrated a significant ability to perform a very high quality work, both theoretical and practical, with a high level of creativity, showing him as a very mature person.
In September 2007 he obtained his M.S. and in October 2010 his PhD degree, both awarded with the Highest Honors. During all the time Manuel stayed with us at the UAB, he was a very active member of the department, offering his knowledge and abilities all the times to all they needed.
Manuel did not go through life without a significant trace. We, his friends and colleagues, will never forget him.
Rest in Peace Manuel.



Ph.D Dissertations: H. Meyer, J. Gramacho, H. Nguyen
On July, 16,17,18 were presented doctoral thesis:
- Hugo Meyer: Fault Tolerance in Multicore Clusters. Techniques to Balance Performance and Dependability.
- João Artur Dias Lima Gramacho: ARTFUL Deterministically Assessing the Robustness against Transient Faults of Programs.
- Hai Nguyen Hoang: A dynamic link speed mechanism for energy Saving in interconnection networks.
Congratulations!!



New postgraduate course at Faculty of Computer Science. UNLP. Argentina.



PhD Thesis Defenses: Hugo Meyer, Joao Gramacho, Hai Nguyen Hoang
Hugo Meyer: Fault Tolerance in Multicore Clusters. Techniques to Balance Performance and Dependability. Date: July, 16, 2014, 12:00am. Auditorium of Engineering School. UAB. Campus Bellaterra.
João Artur Dias Lima Gramacho: ARTFUL Deterministically Assessing the Robustness against Transient Faults of Programs. Date: July, 17, 2014, 12:00am. Auditorium of Engineering School. UAB. Campus Bellaterra.
Hai Nguyen Hoang: A dynamic link speed mechanism for energy Saving in interconnection networks. Date: July 18, 2014, 12:00am. Auditorium of Computer Vision Institute. UAB. Campus Bellaterra.
Cloud Computing Conference. 2014.
Inaugural Conference Efficient use of cloud computing in science, the problem of scalability and their use in simulation Prof. Emilio Luque.
Cloud Computing Conference. July 1, 2014. 16:00 hrs.
Institute for Research in Computer Science. Faculty of Computer Science. UNLP
List of admited Candidates to for HPC4EAS research group open positions.
List of admitted candidates for (alphabetical list):
– Architectures Design to support fault tolerance in high performance computers.
Ahmed Moustafa, Mariam
Bustos, Fabricio
Espínola, Laura
Galarza, Fernando
Quispe, Gloria
Silva Vilela, Guilherme
Villamayor, Jorge
– Designing interconnection networks for specific traffic patterns
Ahmed Moustafa, Mariam
Castro, Alicia
Espínola, Laura
Villamayor, Jorge
Vulchi, Hemalatha
Date: June 30, 2014
Signatures: Professor Tomàs Margalef (Head of Department), Professor D. Rexachs, Professor D. Franco.
Invited talk at the Nanyang Technological University, Singapore (June 6, 2014)
![]() Nanyang Technological University (NTU) is the fastest-rising university in the world’s Top 50 list of universities. Ranked 47th in the world, it is also placed 2nd globally among young elite universities. The university has colleges of Engineering, Business, Science, Humanities, Arts, & Social Sciences, and an Interdisciplinary Graduate School. NTU provides a high-quality global education to about 33,000 undergraduate and postgraduate students.
Nanyang Technological University (NTU) is the fastest-rising university in the world’s Top 50 list of universities. Ranked 47th in the world, it is also placed 2nd globally among young elite universities. The university has colleges of Engineering, Business, Science, Humanities, Arts, & Social Sciences, and an Interdisciplinary Graduate School. NTU provides a high-quality global education to about 33,000 undergraduate and postgraduate students.
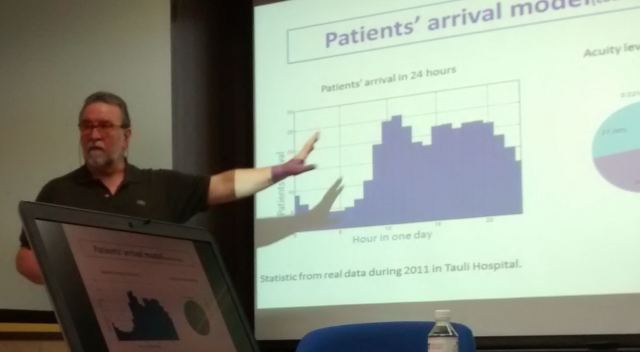
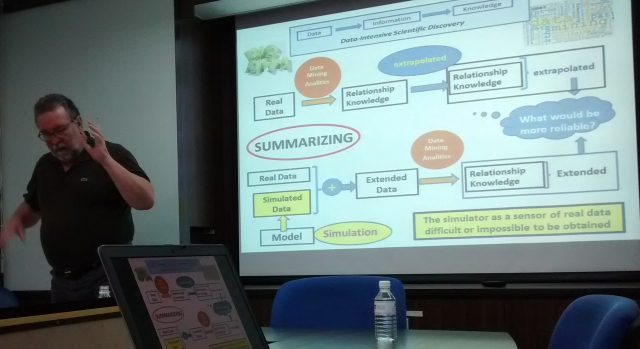
Professor Luque & Professor Rexachs taught a conference where they showed the latest developments in the research group focused on individual oriented model and simulation applied to Emergency Departments as well as new ideas about the utilization of simulation as sensor of the real data that is difficult or impossible to be obtained.
HPC4EAS member participation at the ICCS 2014 – Cairns, Australia (10-12 june).

The International Conference on Computational Science is an annual conference that brings together researchers and scientists from mathematics and computer science as basic computing disciplines, researchers from various application areas who are pioneering computational methods in sciences to discuss problems and solutions in the area, to identify new issues, and to shape future directions for research.
HPC4EAS Group members wil present the papers (published in Elservier Procedia Open Access):
- Optimal Run Length for Discrete-event Distributed Cluster-based Simulations, Pages 73-83, Francisco Borges, Albert Gutierrez-Milla, Remo Suppi, Emilio Luque
- Performance-aware Energy Saving Mechanism in Interconnection Networks for Parallel Systems, Pages 134-144, Hai Nguyen, Daniel Franco, Emilio Luque
- Computing, a Powerful Tool for Improving the Parameters Simulation Quality in Flood Prediction, Pages 299-309, Adriana Gaudiani, Emilio Luque, Pablo García, Mariano Re, Marcelo Naiouf, Armando Di Giusti
- Individual-oriented Model Crowd Evacuations Distributed Simulation, Pages 1600-1609, A. Gutierrez-Milla, F. Borges, R. Suppi, E. Luque
- A Hybrid MPI+OpenMP Solution of the Distributed Cluster-based Fish Schooling Simulator, Pages 2111-2120, Francisco Borges, Albert Gutierrez-Milla, Remo Suppi, Emilio Luque
- Hybrid Message Logging. Combining advantages of Sender-based and Receiver-based Approaches, Pages 2380-2390, Hugo Meyer, Dolores Rexachs, Emilio Luque


HPC4EAS members participation at the V ICT & Health Conference 2014 (5th,6th June, 2014) – Girona.
![]()
The V ICT & Health Conference has as main obectives: contact with the main stakeholders in ICT and health from the territories in the Euroregion, identify research projects and the groups, detect ICT research addressed to social welfare and quality of life & discover new examples of innovation in the territories.
The conference was intended to draw attention to the trends and projects of research in ICT applied to health (eHealth) and to social welfare that are being performed in the territories in the Pyrenees-Mediterranean Euroregion and to encourage international knowledge transfer. It becomes a Forum of technological innovation for sharing solutions, best practices and future trends in health and social welfare. This year the core theme of the conference was innovation in health and welfare.
Five HPC4EAS members participated at the Conference for presenting the work-in-progress & relevant research topics of the group in the area of Simulation & Optimization of Emergency Services in Hospitals (Smarter Health Services). The works presented were:
- An Emergency Department simulator for supporting the decision making and improving the QoS. Z. Liu, E. Luque, D. Rexachs, F. Epelde, E. Cabrera & M. Taboada
- Modeling the contact propagation of nosocomiall infection in Emergency Departments. C. Jaramillo, D. Rexachs, F. Epelde, M. Taboada & E. Luque
http://www.jornadaticsalut.com/en/


This call aims to select 2 candidates for HPC4EAS research group (guidelines for academic studies at UAB-Agreement 57/2006, December 12, UAB Governing Council).
More information: http://www.uab.cat/servlet/Satellite/listado-becas-sin-left-menu/detall-de-l-ajut-1284986965563.html?language=en¶m1=1345671389406¶m2=UAB-FATWIRE&tq=PIF
Open Position Research Lines:
- Architectures Design to support fault tolerance in high performance computers.
- Designing interconnection networks for specific traffic patterns
First phase of the call to support research groups in Catalonia SGR 2014-2016 Program.
On May 9, was published the resolution of the first phase of the call to support Catalonian Research Groups SGR 2014-2016. This first stage gives recognition to the groups presented and now is developing the second phase with external evaluation.
The group HPC4EAS has been selected in this phase and reaches a new challenge as Consolidated Research Group (2014 SGR ID 1562).
AGAUR: http://www.gencat.cat/agaur
Selected Groups (1st phase): http://www10.gencat.cat/agaur_web/generados/catala/home/recurs/doc/resolucio_reconeguts_sgr2014.pdf
A new doctoral thesis proposal in the HPC, Information Theory and Security PhD program.
A new PhD tesis proposal was accepted in the High Performance Computing, Information Theory and Security PhD program.
Doctoral student is:
Pilar Gómez: Impact of Input-Output in High Performance Computing
Congratulations on the new project!!
PhD Thesis Defense: Cristian Tissera
Cristian Tissera: Modelo Basado en Autómatas Celulares Extendidos para diseñar estrategias de Evacuaciones en Casos de Emergencia. Date: April 11, 2013 at 8:30 am. Auditorium of Postgraduate Secretariat. Universidad Nacional San Luis. Argentina.
April 7-14, 2014. Postgraduate courses at the Universidad Nacional de San Luis (Argentina) by HPC4EAS members.
From 7 to 12 April 2014, Dr. Luque, Dr. Rexachs and Dr. Suppi taught postgraduate specialization course Computación Paralela de Altas prestaciones at the National University of San Luis (Argentina) organized by Secretaria de Postgrado (UNSL).
April 3, 2014. HPC4EAS Researchers visited Globant.
After the presentation of the work for Big Data Specialists by Dr. Emilio Luque, a work session was held to discuss how simulation can help in the process of Big Data with the participation of Dr. Dolores Rexachs and Dr. Remo Suppi. https://www.facebook.com/Globant).

 Dr. Luque participated in the session Globant Flipthinking and presented the main issues and solutions in Fault Tolerance for HPC. (https://www.youtube.com/globant))
Dr. Luque participated in the session Globant Flipthinking and presented the main issues and solutions in Fault Tolerance for HPC. (https://www.youtube.com/globant))
